Validateur Robots.txt
Le fichier robots.txt est un fichier texte qui contient des instructions (directives) pour l'indexation des pages d'un site. Grâce à ce fichier, vous pouvez indiquer aux robots de recherche quelles pages ou sections d'une ressource web doivent être explorées et indexées (dans la base de données des moteurs de recherche) et lesquelles ne le doivent pas.
Le fichier robots.txt se trouve à la racine du site et est accessible à l'adresse domain.com/robots.txt.
Pourquoi le robots.txt est-il nécessaire pour le SEO ?
Ce fichier fournit aux moteurs de recherche des instructions essentielles qui influencent directement l'efficacité du classement d'un site dans les résultats de recherche. L'utilisation de robots.txt peut aider à :
- Prévenir l'exploration de contenu dupliqué ou de pages non utiles pour les utilisateurs (comme les résultats de recherche internes, les pages techniques, etc.) par les robots d'exploration des moteurs de recherche.
- Maintenir la confidentialité de certaines sections du site (par exemple, vous pouvez bloquer l'accès à des informations système dans le CMS).
- Éviter la surcharge du serveur.
- Utiliser efficacement votre budget d'exploration pour explorer des pages de valeur.
D'un autre côté, si le robots.txt contient des erreurs, les moteurs de recherche indexeront incorrectement le site, et les résultats de recherche incluront des informations erronées. Vous pouvez également empêcher accidentellement l'indexation de pages utiles nécessaires au classement de votre site dans les moteurs de recherche.
Voici des liens vers des instructions sur l'utilisation du fichier robots.txt fournies par Google :
Contenu du rapport "Erreurs Robots.txt" dans Labrika
Voici ce que vous trouverez dans notre rapport "erreurs robots.txt" :
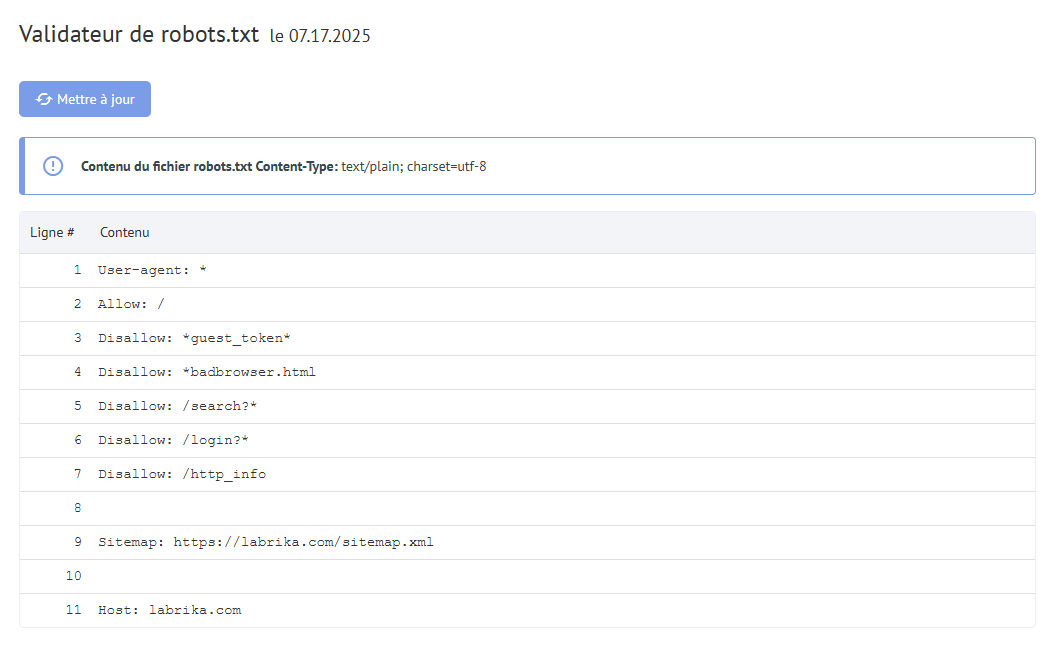
- Bouton "Rafraîchir" - en cliquant dessus, les données sur les erreurs dans le fichier robots.txt seront mises à jour.
- Le contenu du fichier robots.txt.
- Si une erreur est trouvée, Labrika fournit une description de l'erreur.
Erreurs de robots.txt détectées par Labrika
L'outil trouve les types d'erreurs suivants :
La directive doit être séparée de la règle par le symbole ":"
Chaque ligne valide dans votre fichier robots.txt doit contenir le nom du champ, un deux-points, et la valeur. Les espaces sont optionnels mais recommandés pour la lisibilité. Le symbole dièse "#" est utilisé pour ajouter un commentaire, qui est ignoré par le robot d'exploration.
Format standard :
<champ>:<valeur><#commentaire-optionnel>
Exemple d'erreur :
User-agent Googlebot
Caractère ":" manquant.
Option correcte :
User-agent: Googlebot
Directive vide et règle vide
Utiliser une chaîne vide dans la directive user-agent n'est pas permis.
C'est la directive principale qui indique pour quel type de robot de recherche les règles d'indexation suivantes sont écrites.
Exemple d'erreur :
User-agent:
Aucun user-agent spécifié.
Option correcte :
User-agent: le nom du bot
Par exemple :
User-agent: Googlebot ou User-agent: *
Chaque règle doit contenir au moins une directive "Allow" ou "Disallow". Disallow ferme une section ou une page à l'indexation. "Allow", comme son nom l'indique, permet aux pages d'être indexées.
Il n'y a pas de directive User-agent avant la règle
La règle doit toujours venir après la directive User-agent. Placer une règle devant le premier nom d'agent utilisateur signifie qu'aucun robot d'exploration ne la suivra.
Exemple d'erreur :
Disallow: /category
User -agent: Googlebot
Option correcte :
User-agent: Googlebot
Disallow: /category
Utilisation de la forme "User -agent: *"
Lorsque nous voyons User-agent: *, cela signifie que la règle est définie pour tous les robots de recherche.
Exemple d'erreur :
User-agent: *
Disallow: /category
User -agent: *
Disallow: /*.pdf.
Option correcte :
User-agent: *
Disallow: /category
Disallow: /*.pdf.
Directive inconnue
Une directive a été trouvée qui n'est pas prise en charge par le moteur de recherche.
Les raisons peuvent être les suivantes :
- Une directive inexistante a été écrite ;
- Des erreurs de syntaxe ont été commises, des symboles et balises interdits ont été utilisés ;
- Cette directive peut être utilisée par d'autres robots de recherche.
Exemple d'erreur :
Disalow: /catalog
La directive "Disalow" n'existe pas. Une erreur a été commise dans l'orthographe du mot.
Option correcte :
Disallow: /catalog
Le nombre de règles dans le fichier robots.txt dépasse le maximum autorisé
Les robots de recherche traiteront correctement le fichier robots.txt si sa taille ne dépasse pas 500 Ko. Le nombre autorisé de règles dans le fichier est de 2048. Le contenu au-delà de cette limite est ignoré.
Règle dépassant la longueur autorisée
La règle ne doit pas dépasser 1024 caractères.
Format de règle incorrect
Votre fichier robots.txt doit être encodé en UTF-8 en texte brut. Les moteurs de recherche peuvent ignorer les caractères non-UTF-8.
Utilisation de caractères nationaux
L'utilisation de caractères nationaux est interdite dans le fichier robots.txt. Selon le système de nom de domaine approuvé, un nom de domaine ne peut contenir qu'un ensemble limité de caractères ASCII.
Exemple d'erreur :
User-agent: Googlebot
Sitemap: https: //bücher.tld/sitemap.xml
Option correcte :
User-agent: Googlebot
Sitemap: https://xn-bcher-kva.tld/sitemap.xml
Un caractère invalide a pu être utilisé
L'utilisation des caractères spéciaux "*" et "$" est autorisée. Ils spécifient des modèles d'adresse lors de la déclaration des directives.
Le symbole "$" est écrit au milieu de la valeur
Le symbole "$" ne peut être utilisé qu'une seule fois et uniquement à la fin d'une règle.
La règle ne commence pas par "/" ou "*"
Une règle ne peut commencer que par les caractères "/" et "*".
Exemple d'erreur :
Disallow: products
Option correcte :
Disallow: /products
ou
Disallow: *products
Format d'URL de sitemap incorrect
L'URL du sitemap doit contenir :
- L'adresse complète
- La désignation du protocole (HTTP:// ou HTTPS://)
- Le nom du site
- Le chemin vers le fichier
- Le nom du fichier
Exemple d'erreur :
Sitemap: /sitemap.xml
Option correcte :
Sitemap: https://www.site.ru/sitemap.xml
Format incorrect de la directive "Crawl-delay"
La directive Crawl-delay définit la période minimale entre la fin du chargement d'une page et le début du chargement de la suivante pour le robot.
Comment corriger les erreurs du Validateur robots.txt ?
Un fichier robots.txt indique aux robots des moteurs de recherche quelles pages ils peuvent ou ne peuvent pas accéder. Les erreurs typiques et leurs corrections incluent :
- Le fichier robots.txt n'est pas dans le répertoire racine. Pour corriger cela, vous devez simplement déplacer votre fichier vers le répertoire racine.
- Mauvaise utilisation des caractères génériques, tels que * (astérisque) et $ (signe dollar). Si mal placés, vous devez localiser et déplacer ou supprimer ce caractère.
- Accorder l'accès à des sites en développement. Lorsqu'un site est en construction, vous pouvez utiliser l'instruction disallow pour empêcher son exploration, mais une fois lancé, celles-ci doivent être supprimées.
- Ne pas ajouter d'URL de sitemap à votre robots.txt. Une URL de sitemap permet aux robots des moteurs de recherche d'avoir une vue plus claire de votre site.