Pages Bloquées de l'Indexation
Qu'est-ce que l'indexation ?
L'indexation est le processus d'analyse des pages d'un site (normalement effectué par les moteurs de recherche) et, après le crawl, de les ajouter aux index des moteurs de recherche. Cet index (base de données) est ensuite utilisé pour former les résultats de recherche, ainsi que pour le classement des pages dans ces résultats (après que les algorithmes analysent davantage les pages en fonction de la satisfaction de l'intention de recherche et du référencement réussi). L'indexation est réalisée par un robot d'exploration / moteur de recherche.
Pourquoi avons-nous besoin de la possibilité d'exclure des informations des index des moteurs de recherche ?
En règle générale, les informations qui ne doivent pas être affichées dans les résultats de recherche peuvent être bloquées des index des moteurs de recherche en utilisant la balise « noindex » ou en bloquant le crawl de certaines sections/pages du site dans le fichier robots.txt. Les pages normalement bloquées des moteurs de recherche sont de nature technique, propriétaire et confidentielle, et sont jugées inappropriées pour être placées dans les résultats de recherche.
Exemples de pages bloquées
Dans un site commercial, cela peut inclure des liens vers : comptes d'utilisateurs, paniers d'achat, comparaisons de produits, pages en double, résultats de recherche sur le site, etc. Ces pages sont précieuses pour les clients et essentielles au fonctionnement du site, mais ne sont pas utiles pour les index des moteurs de recherche.
Moyens de bloquer des pages de l'indexation par les moteurs de recherche
Il existe plusieurs façons d'empêcher l'indexation des pages :
Utiliser un fichier robots.txt
Le fichier robots.txt est un fichier texte qui indique aux moteurs de recherche quelles pages ils peuvent indexer et lesquelles ils ne peuvent pas indexer. Pour bloquer une page de l'indexation dans robots.txt, vous devez utiliser la directive Disallow.
# Le contenu du fichier robots.txt, # qui doit être dans le répertoire racine du site # autoriser l'indexation des pages et fichiers commençant par '/catalog' Allow: /catalog # bloquer l'indexation des pages et fichiers commençant par '/cart' Disallow: /cart
Utiliser la balise robots avec l'attribut noindex
Pour bloquer une page en utilisant cet attribut, vous devez ajouter les lignes suivantes à la section
de la page :
<meta name="robots" content="noindex">
Utiliser l'attribut nofollow
Il existe deux façons de procéder :
<a href="/page" rel="nofollow"> texte du lien </a>
<meta name="robots" content="nofollow" />
- Bloquer le crawler suivant un lien sur une base de lien par lien :
- Bloquer le crawler suivant tout lien sur la page en donnant à la page elle-même l'attribut nofollow :
Utiliser la balise rel=canonical
L'attribut rel=canonical est utilisé pour indiquer au moteur de recherche que la page est une page canonique (la plus autorisée). Cela indique au crawler que c'est la page préférée à indexer.
<link rel=canonical href="https://example.com/catalog/shirt" />
Comment trouver les pages bloquées de l'indexation sur mon site ?
Vous pouvez consulter cette information dans la section "Audit SEO" - "Pages bloquées de l'indexation" de votre tableau de bord Labrika.
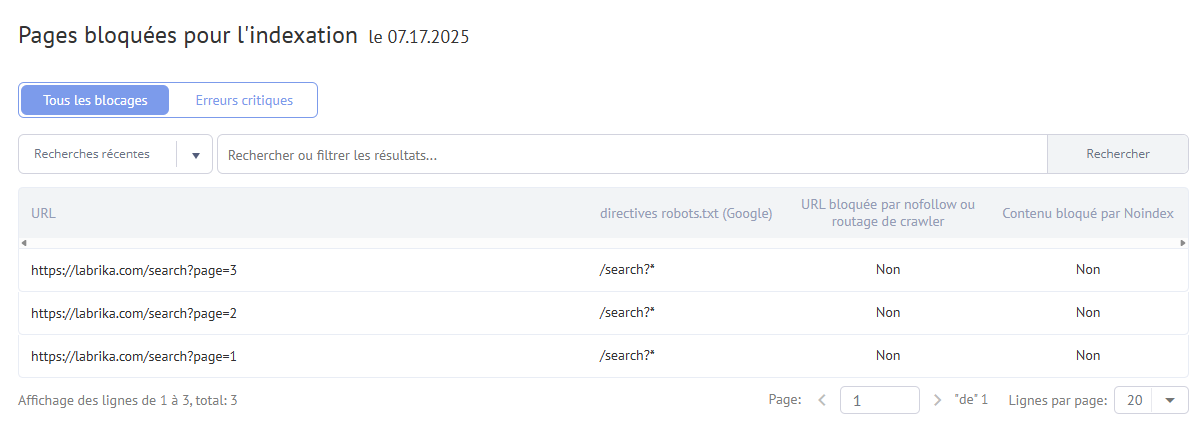
Comment rendre une page indexable à nouveau ?
Dans de nombreux systèmes de gestion de contenu modernes (CMS), vous pouvez modifier le fichier robots.txt, la balise rel=canonical, la balise "robots" meta, ainsi que les attributs "noindex" et "nofollow". Par conséquent, pour rendre à nouveau une page indexable qui figure dans ce rapport, il vous suffit de supprimer l'attribut ou la balise qui empêche cette page d'être indexée. Il existe de nombreux plugins simples qui vous permettent de le faire. Si vous n'êtes pas en mesure de le changer vous-même, il serait relativement simple de confier cette tâche à un développeur.